
Machine learning techniques for exploring influence, commonalities, and shared origin of scripts: cases of Ethiopic, Armenian, Georgian, and Caucasian Albanian scripts
Abstract
The morphological similarities between the Armenian, Georgian, and Caucasian Albanian scripts and the Ethiopic script have long intrigued both casual observers and scholars. However, prior studies have relied primarily on qualitative or historical analysis, often lacking objective or computational rigor. This study addresses that gap by applying machine learning and deep learning methods to explore potential structural relationships among these scripts. Using over 28,000 images of Ethiopic characters, we trained a deep convolutional neural network and augmented the dataset to enhance generalization. The resulting model, FeedelLigence, analyzes cross-script similarities through transformation-invariant distance measures, cosine distance (CD), and mutual information (MI). Our findings indicate notable structural and symbolic proximity between Ethiopic and the three comparison scripts. Armenian showed the strongest similarity, with the highest MI (0.7428 bits) and the lowest CD (0.0774). Georgian and Caucasian Albanian followed, with MI scores of 0.6843 and 0.6561 bits, and CDs of 0.1558 and 0.2498, respectively. These results provide computational evidence of significant structural overlap, suggesting possible historical connections or shared influences. In a broader cultural context, such affinities align with historical patterns of script evolution and cross-civilizational exchange. By combining artificial intelligence with comparative script analysis, this study offers a novel, quantitative perspective on the relationships among ancient writing systems—advancing our understanding beyond traditional human-centered approaches.
1. Introduction
The observed striking similarity of morphology and typology between the Ethiopic script, on the one hand, and the Armenian, Georgian, and Caucasian Albanian scripts, on the other hand, (Fig. 1) had intrigued casual observers and serious academic researchers for some time now (Olderogge 1974; Munro-Hay and Pankhurst 1995; Pankhurst 1998; Bekerie 2003; Guven 2019). This curiosity had found several anecdotal supports from the shared historical and religious interactions, particularly between Ethiopia and Armenia over the past ∼1,600 years (Tamrat 1972; Pankhurst 1976; Fiaccadori 2005; Pogossian 2021). As an important historical tool, writing systems provide a powerful and direct record of past events such as interaction between cultures and civilizations in human thoughts, philosophy, religion, and other shared experiences. The exploration of potential shared connections between these writing systems, therefore, could help unveil hitherto not well-known historical events and cultural interlinkage between their respective societies. In addition, this could also potentially provide an insight into some impacts that the Ethiopic script (that evolved over a period of >2,000 years) may have made beyond the geography of its birthplace. Hence, there is a clearly broader scholarly and historical value in further exploring these potential relationships through the uncovering of new evidence using emerging research tools. While traditional research tools like archaeological artifacts and historical written records have so far been the dominant modes available for collecting evidence and drive discoveries, recent technological advances in information theory, data sciences, and machine learning (ML) have started offering powerful tools and renewed incentives to help uncover the answers to some of these questions. First, however, a concise review of the origins and main features of these scripts is necessary and helpful for developing a historical perspective and context for the main research questions posed here. In the meantime, however, it is also important to note that while the review presented here is based on the latest available literature, more often than not, there is no universal agreement among scholars of writing systems regarding some of these conclusions. As new evidence continues to emerge, previously accepted theories and assumptions are frequently reassessed and challenged. For example, evidence from emerging disciplines like genetics that point to migration from Ethiopia to south Arabia, rather than the reverse, has raised serious doubts about the prevailing assumptions regarding the early origins of Proto-Ge’ez writing systems (Kivisild et al. 2004; Pagani et al. 2012).

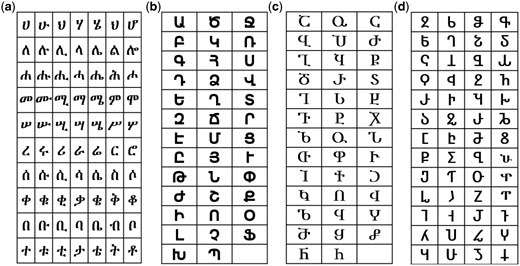
(a) Portions of the Ethiopic script (384 characters for the extended version) (b) Armenian script (liturgical) (thirty-eight characters) (c) Georgian script (Asomtavruli) (thirty-eight characters), and (d) Caucasian Albanian script (fifty-two characters).
1.1 Brief background to Ethiopic, Armenian, Georgian, and Caucasian Albanian scripts
The modern Ethiopic script, with its more than 308 characters, is an abugida (alphasyllabary) writing system that directly evolved from its immediate predecessor, classical Ge’ez, which itself developed from old Ge’ez, a successor to Proto-Ge’ez (Fig. 2). Today, it is used for writing Ge’ez, Amharic, Tigrinya, Tigre, Harari, Gurage, Argobba, Zay, Agew, and other Ethiopian and Eritrean languages (Jensen 1925; Ullendorff 1951; Kobishchanov 1966; Bender et al. 1976; Dagne 1976; Ferguson 1976; Bekerie 1997; Demeke 2009; Weninger 2011; Last et al 2014). Classical Ge’ez, also an abugida writing system, consists of 182 core characters derived from twenty-six basic (root) consonants, twenty labialized characters, and twenty numerals (Bekerie 2003; Demeke 2009). The earliest Proto-Ge’ez writing system, evidenced by monumental inscriptions found in Yeha (Last et al 2014) in Tigray region of northern Ethiopia and Matara (Ullendorff 1951) in today’s Eritrea, originated around the fourth to fifth century BCE. It traces its roots to Proto-Sinaitic scripts, which possibly date to ninth century BCE (Fig. 2). Beginning from around the 1st century CE, the Proto–Ge’ez script, an abjad (consonants only) system of twenty-nine characters, evolved into the old Ge’ez, which adopted a more cursive format of twenty-six characters (five were dropped and two added) and employed a right-to-left writing style. Around 350 CE, old Ge’ez underwent a major transformation into the abugida system of classical Ge’ez, marked by the systematic integration of vowel sounds into the base characters (Bender et al. 1976; Dagne 1976; Ferguson 1976). This significant transformation into fully vocalized syllabary system, motivated primarily by the need for greater efficiency and speed in producing the growing body of Ge’ez literature, particularly the sacred texts of the Orthodox Church, was achieved through the addition of various strokes to the base characters, and in some cases, by modifying one or more sides of the base form itself (Bender et al. 1976; Dagne 1976; Ferguson 1976). It was also during this period that the emerging classical Ge’ez adopted left-to-right (LTR) writing direction, and twenty numerals were incorporated into the script (Bender et al. 1976). Although the contemporary use of classical Ge’ez is primarily limited to liturgical purposes, serving the Ethiopian and Eritrean Orthodox Tewahido and Catholic churches, it remains to be actively used as a literary language in traditional church educational institutions in Ge’ez poetry (qne), grammar, style, and history (Hable Selassie and Tamerat 1970). It is also noteworthy that more than 200,000 manuscripts written in classical Ge’ez script are known to exist today, underscoring its enduring scholarly and cultural importance (Hable Selassie 1981; Nosnitisin 2012).

Historical timeline for the Ethiopic, Armenian, Georgian, Caucasian Albanian, and Odessian (Edessian) scripts and their possible origins. It has to be noted that the exact origins and progressions of particularly the Ethiopic script is not unanimously agreed by scholars in the field and while the depictions are based on the best available sources now, it is not necessarily as linear as shown here. Note that we use the terms “old” and “classical” Ge’ez to distinguish between the “abjad” and “abugida” forms, which have some significant differences.
| Script name | Type of script | Details |
|---|---|---|
| Old Ge’ez (OG) | abjad | Twenty-six characters of consonants, written right to left (RTL). Proto-Ge’ez had twenty-nine |
| Classical Ge’ez (CG) | Abugida (alphasyllabary) | 182 core characters with twenty-six basic (root) consonants + twenty labialized characters + twenty numerals. Total = 242. Written LTR |
| Ethiopic (ET) | Abugida (alphasyllabary) | 238 (34 x 7) core characters + fifty labialized characters + twenty numerals = 308 (total). Its Unicode block has 384 code points. Written LTR. The seven Amharic characters (shared by Tigrigna) are: ሸ ቸ ኘ ዠ ጀ ጨ ቨ |
| Armenian (AR) | alphabetic | Thirty-eight characters. Thirty-six introduced by Mashtots. ‘Օ’ and ‘Ֆ’ were added later |
| Georgian (GO) | alphabetic | Thirty-eight characters in Asomtavruli UNICODE version. Other versions have thirty-three |
| Caucasian Albanian (CAL) | alphabetic | Fifty-two characters. Believed to be introduced by Mesrop Mashtots |
| Odessian (OD) | alphabetic | Twenty-five characters have been identified so far. Remains largely unexplored |
In contrast, the Armenian script is an alphabetic writing system introduced in 406 CE by the Armenian monk Mesrop Mashtots (Dum-Tragut 2009; Megerdichian 2022). The original script had thirty-six characters, with two additional letters added in the tenth to twelfth centuries, bringing the total to thirty-eight. A third letter was added during the Armenian orthography reform of the Soviet Armenia era (Marchesini 2017) but was subsequently dropped. The origin of the Mashtotsian Armenian script is of significant scholarly and historical interest, as it was driven by the quest of the Armenian people for a defining cultural and spiritual identity in the third and fourth centuries CE (Koryun 1962). This effort started with the orders of King Vramshapuh of Armenia (ca. 389–414 CE) and culminated with the subsequent introduction of the Armenian script by Mashtots in 405–06 CE, as supported by the literature from Armenian and non-Armenian sources (Koryun 1962). However, the inspirations that led to the introduction of the Mashtotsian Armenian script continue to be debated. While some scholars have proposed the existence of a pre-Mashtotsian Armenian alphabet (Marchesini 2017), others had suggested that various scripts, ranging from Greek to Ge’ez, served as its prototypes (Olderogge 1974; Arewelts’i and Thomson 1989; Guven 2019). However, evidence suggests before the Mashtots alphabets, the Armenians drew from a combination of writing systems: Greek for artistic and cultural expressions, Latin and Middle Persian for official communication and inscription, and Syriac for liturgical purposes (Sanjian 1996). The Unicode block of the Armenian script spans the U + 0530–U + 058F range, comprising of ninety-one code points (Unicode 1991b).
The Georgian script, the other script of interest, officially has thirty-three characters and is also an alphabetic writing system with three variants (Asomtavruli, Nuskhuri, and Mkhedruli), with Mkhedruli being the dominant one used in today’s everyday language and Asomtavruli representing capital letters (Daniels 1996). The origin of the Georgian script (the Asomtavruli version) and the influences that helped form its creation are not well-established and are still debated. While Georgian sources had argued for its creation by Georgians themselves, there is a growing consensus on possible external influences, possibly through Armenian monks including Mashtots (Rayfield 2020) and—to some extent—the Greek alphabet due to its structural similarity with the Georgian script (Kemertelidze 1999). The discovery of the oldest Georgian inscriptions dating back to 430 CE, timeline that coincides with the years following the introduction of the Mashtotsian Armenian script, has also added more weight to the Armenian influence theory. Notwithstanding the debate regarding its origins, the earlier version of the Georgian script had thirty-eight characters; five were dropped after they became obsolete. The range of Unicode block of Georgian script containing the Mkhedruli and Asomtavruli
1.2 Prior studies
1.2.1 Morphological and typological analysis
| Author | Conclusion |
|---|---|
| Bekerie (2003) | All thirty-eight Armenian characters may have come from a family of seven core Ethiopic characters |
| Sevak (1962) | Suggested Ethiopic as a possible inspiration for the Armenian script |
| Olderogge (1974) | Suggested Ethiopic as a possible inspiration for the Armenian script |
| Kobishchanov (1966) | He supposes that a Syrian (Bishop Daniel) may have introduced it to Armenia |
| Pankhurst (1998) | Quotes Olderogge, Turaev (1912) and Conti Rossini (1942) to point similarity |
| Munro-Hay (2002) | Quotes Olderogge that Ethiopic may have influenced Armenian |
1.2.2 Machine learning approaches
In the meantime, however, progress in modern digital technology, especially ML and information theory offers a new opportunity to explore and re-examine these questions. These modern computational tools can help explore key properties of these scripts such as entropy of geometries, nearness and distances, classifications, feature extractions, and spatial patterns. In addition, these tools can also help determine, in a comparative way, local relationships, underlying structures, dimensional reductions, lower-dimensional representation of images, and shape analysis of these scripts. In particular, the style, design, and form of the individual characters could be explored, with special focus on the geometry and topology of the unique strokes in the Ethiopic script that are also shared by the other scripts under consideration.
As a background to the potentials applications of these modern digital tools, several exploratory studies in ML related to the Ethiopic script have been reported (Abebe et al 2004; Birhanu and Sethuraman 2015; Weldegebriel et al. 2018; Demilew and Şekeroglu 2019; Grieggs et al 2023). A recent study by Demilew et al. proposed an offline ancient Ge’ez document recognition system using deep convolutional neural network (CNN) in which the CNN integrates an automatic feature extraction and classifications layers for optical character recognition (OCR) applications. Their system achieved an optimal accuracy of 99.4 per cent and loss of 0.044 with preprocessing steps applied. In a separate study, Weldegebriel et al, developed a Ge’ez OCR system employing both CNN and a forward multilayer perceptron architecture. Grieggs et al. introduced an open-source tool that transcribes images of Ge’ez manuscript pages using a convolutional recurrent neural networks approach tailored for OCR applications. Birhanu et al. applied CNN model trained on dataset of 132,500 handwritten Amharic characters. Collectively, these studies demonstrate the usefulness of ML techniques for training models capable of feature extraction and classification for Ethiopic and related scripts. However, these studies almost exclusively focus on OCR technology as both the means and the end in itself.
To provide context with regard to the use of ML and deep learning (DL) techniques in other historical scripts, the cases of ancient languages such as Arabic, Hebrew, and Siamese in script processing could provide a robust example. For example, ML and DL have been used in Ancient Hebrew to address core challenges in textual dating and semantic analysis (Naaijer et al. 2022). DL has been used for temporal or period classification of historical Hebrew texts, where sophisticated models such as CNNs and RNNs were demonstrated to significantly outperform traditional supervised ML algorithms in classifying texts based on their assumed writing period (Liebeskind et al. 2025). In the case of Arabic script, DL has been employed to historical Arabic texts for recognizing ancient Arabic characters as well as for exploring the historical evolution of the Arabic lexicon (Bouchantouf et al. 2025). By computing word similarity matrices across arbitrary time periods, the continuous semantic shifts were analyzed and categorized directly addressing how word meanings evolved over the centuries (Kiyama et al. 2025). There is also a growing literature on recent ML and DL research on the Siamese (Thai) language predominantly focused on modern, practical applications rather than on its deep historical origins or reconstruction of proto languages (Waijanya and Promrit 2018).
In this current study, we introduce DL approaches to the Ethiopic script and explore the existence of supporting evidence that may help establish convincing arguments and evidence regarding the compelling similarities—or lack thereof—between the Ethiopic, Armenian, Georgian, and Caucasian Albanian scripts, and, in the process, uncover fundamental insights into the potential relationships and shared history underlying these similarities. In the initial phase, we employ PCA (principal component analysis) for dimensionality reductions. With this tool, we expect to get a first pass on identifying close geometrical features and relationships between the scripts under consideration. In the second phase, we use DL techniques through CNN analysis to train a model based on a large dataset of the Ethiopic script for a more nuanced and rigorous exploration of the nearness and distances between characters in these scripts. Using this network as a feature extractor, the distance between the query image and the search image will be measured and similar images of the characters of the individual scripts retrieved. As control experiments and to expand our test dataset, we include Proto–Ge’ez (also known as Sabean or Old South Arabian) and Latin scripts in testing the models.
2. Methods
In this study, we use DL and PCA to explore the relationships between these selected scripts. PCA, which projects high-dimensional data onto lower dimensional spaces, was implemented using the Python scikit-learn library. For the purpose of analysis, the first four principal components of each script were selected. For DL, in brief, our approach combines CNNs, metric learning, and unsupervised visualization tools to quantitatively and qualitatively examine inter-script relationships. The first step in this process involves identifying a comprehensive and representative dataset for the scripts of interest, followed by grouping and labeling classes of Ethiopic character sets based on similar image morphology, and then subsequently using these for training a model.
2.1 Data collection, preparation, and processing
We sourced ∼32,000 images of Ethiopic alphabet characters from GitHub for training our DL model (Hailu 2024). These images represent a wide variety of topography of hand-written Ethiopic characters. As this database contained the extended Ethiopic script with its more than 384 characters, a further cleanup was necessary to retain only the characters belonging to the classical Ge’ez subset (182 characters), which were in use during the historical period of interest when potential interactions may have occurred. As a control, we also included the additional seven base characters used by Amharic and Tigrigna. This refinement reduced the dataset to 28,092 characters, out of which 80 per cent of the dataset (22,492 images) was allocated for training, while the remaining 10 per cent of the dataset (2,800 images) were reserved for testing and another 10 per cent (2,800 images) for evaluation purposes. Related to this, it is important to mention that for the discussions here, we have opted to continue using the name “Ethiopic” instead of “classical Ge’ez” to refer to this particular character datasets. Figure S1 (see online supplementary material for a colour version of this figure) shows part of the training data.
The images that represented the characters in each test and control script were then resized to 28 × 28 pixels (Fig. S2—see online supplementary material for a colour version of this figure). Unicode characters corresponding to the test scripts (Armenian, Georgian, and Caucasian Albanian) and the control scripts (Proto–Ge’ez and Latin scripts) were added to the test dataset. For the Armenian script, the “liturgical” variant was used, consisting of thirty-eight characters within the Unicode range U + 0530–U + 0556. For the Georgian script, the Asomtavruli version (capital letters and church literature) with Unicode range of (U + 10A0–U + 10C5) and thirty-eight characters was adopted, while for the Caucasian Albanian, the Unicode range of (U + 10530–U + 10563) with fifty-two characters was considered. For the Proto-Ge’ez (Sabean—old South Arabian) script, on the other hand, the Unicode range of (U + 10A60—U + 10A7C) was used, encompassing twenty-nine characters (Fig. S3—see online supplementary material for a colour version of this figure). The selection of liturgical version of Armenian script and Asomtavruli variant of Georgian script is based on the historical timelines of their respective origins which align with the period of our interest (fourth to fifth century CE) where the first potential cultural interactions among these civilizations may have occurred. All image files for all these scripts were then pre-processed through normalization (where the pixel values were scaled to the range [0, 1] by dividing by 255), grayscale conversion (all images were converted to grayscale to simplify the model input), binary conversion, and data augmentation (for enhancing model robustness and prevent overfitting, transformations such as rotation, mirror imaging (horizontal and vertical) were considered). The data augmentation prepared the dataset for data labeling, where Ethiopic characters with similar geometric structures could be grouped together. Ultimately, these image files served as data points for the DL model, providing a robust foundation for analysis.

Grouping and labeling classes of Ethiopic character sets based on similar image morphology.
2.1.1 Ground truth and labeling
To enhance model robustness and reduce intra-class variability, we consolidated the Ethiopic script character sets into 143 distinct classes by systematically applying geometric transformations such as rotation and mirroring (Fig. 3). Characters that exhibited high visual and structural similarity under these transformations were grouped into unique classes. This process resulted in a 40 per cent reduction in the total number of classes, yielding a more compact and semantically meaningful label space. The reduction not only mitigates the effects of superficial visual differences but also strengthens the discriminative power of the learned embeddings when training with a ResNet34-based deep CNN using triplet loss. Furthermore, this strategy improves generalization, accelerates convergence during training, and contributes to more coherent clustering patterns in downstream dimensionality reduction and visualization tasks. For example, as shown in Figs 3 and S1, G1 (group 1) consists of three Ethiopic characters of “ሀ በ ር”, while G2 (group 2) and G3 (group 3) consist of “ላ ሳ ሶ” and “ዩ ዪ ዬ”, characters, respectively. The rationale is that these sets of Ethiopic characters within a given group are geometrically similar, and other characters in the same group could be generated through basic geometrical transformations, such as mirroring or rotations. For example, in the G1 class, which represents the “ሀ በ ር” group, the second Ethiopic character ‘በ’ can be easily derived from the first character ‘ሀ’ through horizontal mirror imaging. Similarly, the last character ‘ር’ can be obtained by rotating ‘ሀ’ 90° clockwise. Likewise, in G3, the “ሶ” character can be derived from “ሳ” through simple vertical mirroring. See Sections S.2.1 for further details on the characters classes.
2.1.2 Invariance-aware similarity metrics
To enhance the model’s invariance to rotation, mirroring, and scaling transformations, we systematically applied these transformations to the test images. For each transformed instance, we computed cosine distance (CD) and mutual information (MI) between embeddings. The optimal threshold was determined by selecting the transformation state (e.g., rotation angle, mirroring direction) that minimized CD and maximized MI. This strategy ensures that character similarity is assessed as invariant to geometric transformation, thus better reflecting script-level relationships.
2.1.3 Dimensionality reduction and model performance
To explore and visualize the structure of learned feature spaces, we used t-Distributed Stochastic Neighbor Embedding (t-SNE). This method facilitates comparative and cluster-based analysis of script relationships. The visualizations were used to interpret how character sets from different scripts relate to each other in terms of visual and structural features. Model performance was assessed through intra- and inter-script distance distributions using CD and MI, followed by top-5 prediction results. The evaluation included both quantitative metrics (average distance, subsequent threshold accuracy) and qualitative visualization (clustering patterns in PCA and t-SNE projections). A careful analysis was performed to determine whether observed similarities correspond to historical hypotheses of shared origin or convergent evolution.
2.2 Design of convolutional neural network for cross-script analysis
In this study, we introduce “FeedelLigence”, a custom DL model built on CNN architecture. FeedelLigence is optimized for feature extraction from high-dimensional character representation data. The model processes input sequences using multiple convolutional layers that capture local dependencies and recurrent structures, followed by pooling layers for dimensionality reduction and fully connected layers for classification or similarity scoring. FeedelLigence is trained using supervised learning paradigms and incorporates regularization techniques to prevent overfitting. This architecture allows the model to generalize well across typologically distinct scripts and to detect subtle patterns that may point to deep historical relationships or convergent script evolution (Fig. 4). Our implementation enables the scalable analysis of large corpora and supports cross-linguistic comparison. As such, FeedelLigence serves as both a computational tool for hypothesis testing and a potential framework for advancing quantitative methodologies in historical and comparative study of writing systems.

Architecture of FeedelLigence. This consists of several convolutional layers, grouped into four residual blocks (layer 1 to layer 4), with each block containing a series of “BasicBlock” layers.
2.2.1 Model construction
This DL model FeedelLigence is developed by leveraging a pretrained ResNet34 architecture as a feature extractor. This architecture is considered effective in image classification tasks and enables the model to learn meaningful representations of Ethiopic characters in a high-dimensional feature space. In other words, the primary goal is to learn a unified representation space where visually or structurally similar characters from different scripts are embedded close together. The network accepts 28 × 28 × 3 RGB character images and processes them through a series of convolutional and residual layers to extract multi-scale, script-sensitive features. To further enhance the model’s ability to differentiate between distinct character classes, we incorporated a triplet loss function. This metric learning approach ensures that characters from the same class are projected closer together in the embedding space while characters from different classes are pushed further apart.
As shown in Fig. 4 and S4 and detailed in Section S.2.2 (see online supplementary material), the architecture comprises several convolutional layers, grouped into four residual blocks (Layer 1 to Layer 4), each consisting of a series of “BasicBlock” layers. These blocks are composed of convolutional layers with batch normalization and ReLU activations, enabling the network to learn complex feature representations. Each residual block also includes skip connections, which allow the network to learn identity mappings and enhance gradient flow throughout the network. The architecture begins with an initial convolutional layer (7 × 7 kernel, stride of 2) designed to capture low-level visual features. This is followed by batch normalization, ReLU activation, and max pooling for down sampling. It then passes through four main residual stages. Layer 1 consists of three basic residual blocks with sixty-four channels to extract mid-level shape patterns. Layer 2 uses four blocks (up to 128 channels) to learn more intricate structural features. Layer 3 deepens the network with six blocks and 256 channels, enabling the extraction of detailed character-specific features. Layer 4 contains three blocks with 512 channels, allowing the network to capture high-level, global character representations. Finally, an adaptive average pooling layer reduces spatial dimensions, followed by a fully connected layer that outputs a 143-dimensional embedding vector. This embedding serves as the basis for computing character similarity across scripts using the triplet loss objective. The pre-trained weights from the ResNet34 model are used as a starting point, enabling the model to leverage learned features and perform well even with limited data. This architecture is well-suited for character recognition tasks, as it is capable of capturing both local and global features from input images.
2.2.2. Model performance
As shown in Fig. S5 (see online supplementary material for a colour version of this figure), the training process over the first 100 epochs demonstrates a stable and effective learning curve, with the model achieving a consistent improvement in performance metrics. Validation accuracy steadily increases and stabilizes around 98.1 per cent, while Top-1 and Top-5 accuracies reach approximately 99.4 per cent and 99.99 per cent, respectively, indicating high precision in predictions. Concurrently, the loss value decreases significantly from 2.74 to ∼1.38, reflecting the model’s convergence and reduced prediction error. These results suggest that the model generalizes well on the validation set and is capable of distinguishing complex patterns with high confidence, making it suitable for deployment in tasks requiring fine-grained classification accuracy. Figure 5 shows a two-dimensional t-SNE

Two-dimensional t-SNE
2.2.3 Computation of similarities through cosine distance and entropy metrics
To quantify the structural similarity or divergence between Ethiopic characters and characters from the other writing systems, we used cosine similarity and entropy-based metrics. Cosine similarity was calculated for each character in the target script against all Ethiopic classes, using an algorithm that incorporated geometric transformations, including mirror imaging (horizontal and vertical) and rotation in 10° increments up to 360°. As illustrated in Fig. 6, we first preprocess each input image and extract its feature embedding using the designated model. This initial embedding serves as the reference representation of the original image. We then augment the image with a comprehensive set of geometric transformations to examine orientation and reflection invariance. Specifically, each image is rotated in fixed 20° increments across the full 0°–360° range, yielding a series of rotated versions (e.g., at 0°, 20°, 40°, …, 360°). For each such rotated image, we additionally generate mirrored variants by reflecting the image across the horizontal (x-axis) and vertical (y-axis) directions. This process produces a diverse set of transformed images that encompass all possible combinations of rotations and mirror reflections of the original.

Cosine distance measurement algorithm.
For each transformed image (rotated and/or mirrored), we compute an embedding vector using the same feature extraction method applied to the original image. These transformed embeddings capture how the character’s representations change under different geometric transformations. Finally, to quantify the similarity between the original image’s features and those of its transformed counterparts, we calculate the cosine similarity between the original image’s embedding and each of its transformed counterparts. For each rotation angle and its mirrored versions, we identify the transformed version that yields the highest cosine similarity with the original embedding. This process yields, for each input character, a maximum similarity score that reflects the highest degree of embedding consistency under rotation and mirroring transformations. From these comparisons, we identify the top-5 best-matching classes. Figure S6 (see online supplementary material for a colour version of this figure) summarizes the procedure used for selecting these top five probabilities. This approach leverages the model’s output (which is typically a probability distribution for each 143 class) and extracts the top five most probable predictions. After passing the 28 × 28 character images through the model, the resulting vector of class probabilities or logits for each 143 class at softmax layer is filtered by selecting the top five values. After determining the top five probabilities, a threshold was applied to each output using distance metrics (CD) and entropy (MI) metrics.
In addition to cosine similarity, we computed the MI and entropy values to assess character similarity and also measure uncertainty. After training the model, we computed entropy values between paired characters identified by the model. A lower entropy value between two characters suggests a higher likelihood of shared origin. Entropy was also used to cluster similar characters across scripts—pairs with low entropy were grouped together as potentially deriving from the same “ancestral” form. Furthermore, cross-entropy loss was used during model training, and post-training softmax outputs were analyzed using entropy to quantify the distinctiveness or similarity of character representations.
3. Results
3.1 Visual inspection of topology and form
As a preliminary step, we established a baseline for our exploration through a visual inspection of the similarities among the characters in the scripts under consideration. This approach is what Bekerie, Olderogge, and Sevak had used (Sevak 1972; Olderogge 1974; Bekerie 2003). Figure 7 summarizes these findings where twenty-nine out of thirty-eight of the Armenian characters (76 per cent) appear substantially similar to their Ethiopic counterparts. Arguably, the character “Խ” resembles a combination of two Ethiopic characters “ለ” and “ሀ.” Similarly, eighteen out of thirty-eight characters in Georgian script (47.4 per cent) have strong resemblance to Ethiopic characters. In the case of Caucasian Albanian script, thirty out of its fifty-two characters (57.7 per cent) have substantial similarity with Ethiopic script, representing the largest number of similar characters. While based on visual pattern recognition and thus subject to interpretation, these observations nonetheless provide a promising starting point for more rigorous analysis using PCA and DL techniques.

Visual analysis of similarity between characters (a) Armenian and Ethiopic (twenty-nine out of thirty-eight appear very similar (76 per cent)) (b) Caucasian Albanian and Ethiopic (thirty-one out of fifty-two appear very similar (59.6 per cent)) (c) Georgian and Ethiopic (eighteen out of thirty-eight characters appear very similar (47.4 per cent)). The Ethiopic characters use the Ebrima typeface.
3.2 Principal component analysis for decomposition and clustering
The comparison of the first four principal components between these scripts shows useful correlations. For example, as shown in Fig. 8, PC1 vs PC2 for Ethiopic, Armenian, Georgian, and Caucasian Albanian scripts show an area of correlation concentrated in the middle. Further, the PC1 vs PC2 plots of Ethiopic and Armenian scripts tend to overlap significantly, except few outlier characters. These characters that overlap coincide with what was determined visually in Section 3.1. The comparison between Ethiopic and Georgian also has some close overlaps, but at lesser degree than its Armenian counterpart. The most spread-out relationship is found with Ethiopic vs Caucasian Albanian comparison. The PC3 vs PC4 comparisons also follow the same trend as shown in Fig. 8a. Further breakdown analyses are given in Figs S7 and S8 (see online supplementary material for a colour version of these figures).

(a) PC1 vs PC2 distributions for Ethiopic, Armenian, Georgian, and Caucasian Albanian scripts (b) PC3 Vs PC4 distributions for Ethiopic, Armenian, Georgian, and Caucasian Albanian scripts.
3.3 Convolutional neural network using FeedelLigence model
3.3.1 Similarity analysis through probability of matches
The probabilities of matches identified by the FeedelLigence model for each of the scripts with that of the Ethiopic script are summarized in Fig. 9. Taking only the top probability of matching, the predicted similarities between Ethiopic and Armenian vary from 100 per cent to a low of 48 per cent with mean = 85 per cent and standard deviation (SD) = 15 per cent. Out of the thirty-eight Armenian characters, twenty-seven (72 per cent) have >80 per cent similarities with Ethiopic character set. On the other hand, if the top three probabilities of matching are considered (Fig. S9—see online supplementary material for a colour version of this figure), the similarities increase to a mean of 91 per cent with SD = 9 per cent, where 34/38 (89.5 per cent) of Armenian characters have >80 per cent similarity with Ethiopic character sets. Here, we selected 80 per cent similarity threshold as an adequate representation of significant relationships. A histogram of similarities is presented in Fig. 10a.

Similarities between Ethiopic and the other three test scripts identified using deep learning techniques (top 1 probability match). (a) The similarities between Ethiopic and Armenian scripts as predicted by FeedelLigence vary from 100 per cent to a low of 48 per cent (b) For Ethiopic vs Georgian, the variation is from 100 per cent to a low of 28 per cent (c) For Ethiopic vs Caucasian Albanian, the variation is from 100 per cent to a low of 31 per cent.

(a) Histogram summary of similarities of the test scripts with top 1 picks (b) comparison of predictions of similarity between FeedelLigence (top 1 probability of match) and visual inspection for the three test scripts.
| Writing system | Probability level | Minimum match (per cent) | Mean (per cent) | Standard deviation (per cent) | Number of characters >80 per cent match | Per cent >80 per cent match | Visual |
|---|---|---|---|---|---|---|---|
| Armenian (AR) | Top 1 | 48 | 85 | 15 | 27/38 | (71 per cent) |
|
| Top 3 | 58 | 91 | 9 | 34/38 | (89.5 per cent) | ||
| Georgian (GO) | Top 1 | 28 | 80 | 20 | 21/38 | (55.3 per cent) |
|
| Top 3 | 65 | 93 | 7 | 32/38 | (84.2 per cent) | ||
| Caucasian Albanian (CAL) | Top 1 | 31.23 | 77.3 | 21 | 23/52 | (44.2 per cent) |
|
| Top 3 | 31.23 | 89.4 | 10 | 36/52 | (69.2 per cent) |
3.3.2 Similarity analysis through entropy, cosine distance, and mutual information metrics
For a more rigorous analysis, the CD metric was employed to assess the similarity between embeddings of Armenian, Caucasian Albanian, and Georgian characters relative to the reference Ethiopic script. Lower CDs indicate higher embedding similarity. MI was also calculated to quantify the amount of shared information between the character distributions of each script and the reference Ethiopic script, with higher MI values indicating a stronger informational correspondence. The outputs from the AI model FeedelLigence regarding the similarities between Ethiopic character sets and Armenian, Georgian, and Caucasian Albanian character from CD and MI point of view are summarized in Figs 11–13. As a threshold, prediction accuracy exceeding 75 per cent, with CD ≤ 0.5 and MI ≥ 0.5 bits was selected as a key criterion for evaluating significant relationships. As shown in these figures, the Armenian script consistently exhibits the lowest average CD among three test scripts with an average of 0.0774 and a range of 0.0262–0.1472 (Fig. 11). It also exhibits the highest mean MI of 0.7428 bits across the test set, with a corresponding range of 0.5967–0.8946 bits (Fig. 12). In fact, several characters show exceptionally strong similarity such as “Ջ” (JHEH) with a CD of 0.0271 and MI value of 0.8946 bits and “Ծ” (CA) with a CD of 0.0262 and MI value of 0.8631 bits. In general, the Armenian script yielded the highest MI values (across the test scripts), with most characters ranging between 0.70 and 0.90 bits and scoring 100 per cent probability of similarity (e.g., Ո, Ռ, Թ, Ս, Մ, Կ, Ն, Ջ, Ի, Դ, Պ, Ք, Փ, Գ, Ը, Ց, Ւ, and Հ). This finding underscores a strong informational alignment, suggesting that Armenian characters retain significant shared features with the reference Ethiopic script.

Summary of numerically sorted CD comparison between the five scripts (a) lumped together and (b) plotted linearly. The x-axis in (a) represents the order of the characters in the scripts.

Summary of MI comparison between the five scripts (sorted from highest to lowest) (a) lumped together and (b) plotted linearly. The x-axis in (a) represents the order of the characters in the scripts.

Summary of CD and mutual information comparison between the four scripts (test and reference) plotted together (a) Armenian script (b) Georgian script and (c) Caucasian Albanian script.
The Caucasian Albanian script, on the other hand, with an average CD of 0.1558 in the range of 0.0275–0.2864 and an average MI of 0.6561 bits with a corresponding range of 0.5016–0.7886 bits, demonstrates moderate CD and MI values with a wider variance compared to Armenian script. While all characters in this script meet the threshold criteria, the strongest similarities are observed in the character “ ” (ALT) which has a CD of 0.0275 and MI of 0.6022 bits and the character “
” (ALT) which has a CD of 0.0275 and MI of 0.6022 bits and the character “ ” (PEN) with a CD of 0.0524 and MI value of 0.5969 bits. The character “
” (PEN) with a CD of 0.0524 and MI value of 0.5969 bits. The character “ ” (DZAY) has also a notable high MI value of 0.7886 bits. Other notable Caucasian Albanian characters with relatively small CD, high MI, and ∼100 per cent probability of similarities are
” (DZAY) has also a notable high MI value of 0.7886 bits. Other notable Caucasian Albanian characters with relatively small CD, high MI, and ∼100 per cent probability of similarities are  and
and  In general, while certain characters showed close proximity to the reference embeddings, others were more dispersed, indicating a partial overlap in learned representation. These results imply a fair degree of information retention, aligning with their intermediate performance in CD evaluation. In the case of the Georgian script, the average CD is 0.2498 with a range of 0.0657–0.4959 while the average MI value is 0.6843 bits with a corresponding range of 0.5681–0.7637 bits. This represents comparatively lower MI scores, particularly for Georgian characters such as “Ⴂ,” “Ⴄ”, and “Ⴈ.” A notable similarity with Ethiopic characters is observed in the Georgian capital letter “Ⴀ” (AN) that has CD score of 0.0657 and MI value of 0.7069 bits and “Ⴄ” (EN) with a CD of 0.0899 and MI of 0.6569 bits. Other notable Georgian characters with CD and MI values within the threshold and ∼100 per cent probability of similarity are Ⴖ, Ⴗ, Ⴙ, Ⴤ, Ⴈ, Ⴂ, Ⴔ, Ⴕ,
In general, while certain characters showed close proximity to the reference embeddings, others were more dispersed, indicating a partial overlap in learned representation. These results imply a fair degree of information retention, aligning with their intermediate performance in CD evaluation. In the case of the Georgian script, the average CD is 0.2498 with a range of 0.0657–0.4959 while the average MI value is 0.6843 bits with a corresponding range of 0.5681–0.7637 bits. This represents comparatively lower MI scores, particularly for Georgian characters such as “Ⴂ,” “Ⴄ”, and “Ⴈ.” A notable similarity with Ethiopic characters is observed in the Georgian capital letter “Ⴀ” (AN) that has CD score of 0.0657 and MI value of 0.7069 bits and “Ⴄ” (EN) with a CD of 0.0899 and MI of 0.6569 bits. Other notable Georgian characters with CD and MI values within the threshold and ∼100 per cent probability of similarity are Ⴖ, Ⴗ, Ⴙ, Ⴤ, Ⴈ, Ⴂ, Ⴔ, Ⴕ,  and Ⴀ. However, while the majority of the Georgian characters fall within the established thresholds, it, nonetheless, revealed the highest mean CD, with certain symbols (e.g., “Ⴒ1” and “Ⴘ”) reaching values as high as 0.75. This suggests a greater representational divergence, implying either structural uniqueness in the script or lower model confidence in embedding alignment or reduced informational overlap, which may be attributed to script-specific complexities or less effective representation learning.
and Ⴀ. However, while the majority of the Georgian characters fall within the established thresholds, it, nonetheless, revealed the highest mean CD, with certain symbols (e.g., “Ⴒ1” and “Ⴘ”) reaching values as high as 0.75. This suggests a greater representational divergence, implying either structural uniqueness in the script or lower model confidence in embedding alignment or reduced informational overlap, which may be attributed to script-specific complexities or less effective representation learning.
 ” scoring CD value of 0.178 and MI value of 0.8787 bits, “
” scoring CD value of 0.178 and MI value of 0.8787 bits, “ ” with a CD of 0.0401 and MI of 0.6052 bits and “
” with a CD of 0.0401 and MI of 0.6052 bits and “ ” with a CD of 0.0477 and MI of 0.6877 bits. In general, the Proto-Ge’ez script yielded the highest MI values of all the five tested scripts with most characters scoring 100 per cent probability of similarity (e.g.,
” with a CD of 0.0477 and MI of 0.6877 bits. In general, the Proto-Ge’ez script yielded the highest MI values of all the five tested scripts with most characters scoring 100 per cent probability of similarity (e.g.,  ). The other control script, Latin, showed an average CD of 0.1272 with a range of 0.0637–0.2245 and an average MI value of 0.6039 bits and a corresponding range of 0.4595–0.7658 bits. Notably, the Latin script demonstrates moderate similarity metrics with several characters falling below MI threshold of 0.5 bits, for example: M (0.4897), P (0.4687), B (0.4595), and F (0.4974). Table 4 provides a comparison of MU content, CD, and MI predicted by FeedelLigence while Figs
). The other control script, Latin, showed an average CD of 0.1272 with a range of 0.0637–0.2245 and an average MI value of 0.6039 bits and a corresponding range of 0.4595–0.7658 bits. Notably, the Latin script demonstrates moderate similarity metrics with several characters falling below MI threshold of 0.5 bits, for example: M (0.4897), P (0.4687), B (0.4595), and F (0.4974). Table 4 provides a comparison of MU content, CD, and MI predicted by FeedelLigence while Figs | Writing system | MU content (bits) | Mean cosine distance (CD) | CD range | Mean MI (bits) | MI range (bits) | Notes (Cosine distance and MI) |
|---|---|---|---|---|---|---|
| Armenian (AR) | 21.49 | 0.0774 |
|
0.7428 |
|
|
| Caucasian Albanian (CAL) | 14.39 | 0.1558 |
|
0.6561 |
|
|
| Georgian (GO) | 11.16 | 0.2498 |
|
0.6843 |
|
|
| Proto-Ge’ez (Sabean) | 13.92 | 0.2056 |
|
0.7726 |
|
|
| Latin | 10.10 | 0.1272 |
|
0.6039 |
|
|
 (0.0275, 0.6022),
(0.0275, 0.6022), (0.0524, 0.5969)
(0.0524, 0.5969) (c0.0401, 0.6052),
(c0.0401, 0.6052), (c0.0477, 0.6877)
(c0.0477, 0.6877)
Comparison of mean MI and CD across the scripts considered here. Proto-Ge’ez script has the highest mean MI, while the Armenian script (AR) has the lowest CD.
4. Discussions
The results obtained from PCA and visual inspection give the first pass in terms of determining relationship between these scripts. As expected, the outcomes from our visual analysis are consistent with earlier findings that had used a similar approach (Sevak 1962; Olderogge 1974). Bekerie had reported that all the thirty-eight Armenian characters may have come from the seven family of Ethiopic characters (Bekerie 2003) However, our conservative analysis puts the number of matching characters as twenty-nine. Olderogge had used a similar visual analysis based on “imagery, structure, and stylistic features” of the Armenian characters to report that at least eight of the characters had “almost identical correspondences” (Olderogge 2022). He further commented that 22–23 of Mashtots’ original Armenian characters (two-third of the alphabet) follow the Ethiopic diacritic marking principles. The PCA outcomes are also broadly consistent with the visual inspection outcomes, where the Armenian script seems to have a distribution closer to the Ethiopic script compared to the other test scripts. The higher-order components (PC3, PC4, etc.,) also did not show any surprises. However, because they consider only the given limited data represented by modern fonts and do not inherently allow any training through a broader dataset that captures the variations in the morphology of these characters such as hand-written versions, their usefulness is limited. On the other hand, the DL model FeedelLigence reveals intricate details on the comparison between these scripts.
4.1 FeedelLigence deep learning model predictions with new revelations
The results from the FeedelLigence model, based solely on computational similarity metrics (disregarding historical context), reveal several interesting patterns across the examined scripts. This DL approach uncovers latent symbolic and structural proximity that bypasses linguistic or historical assumptions. Starting with the control test sets, the close proximity predicted for the Proto-Ge’ez script (control test set) is as expected, where it demonstrated the highest MI average (0.7726 bits), indicating significant information sharing and shared ancestral elements with deeper conceptual relationship beyond visual appearance with Ethiopic script. The model also accurately captured some of the historical nuances such as assigning low similarity and dependence with the Proto-Ge’ez characters like “ ” that were dropped by old Ge’ez while identifying a good similarity to characters like “
” that were dropped by old Ge’ez while identifying a good similarity to characters like “ ” that were adopted by old Ge’ez after simple rotation. This is also notable given that the Proto-Ge’ez characters are inherently more angular and sharper than their Ethiopic counterparts. With regard to Latin script, the outcomes are as expected for this control script, which showed the lowest average MI with Ethiopic script with several characters falling below the threshold. The smallest CD (average: 0.0774) and consistently highest MI values (average: 0.7428 bits) predicted for the Armenian script represent one of the key findings of this study which is establishing Armenian script, based purely on the quantitative metrics and focusing solely on the machine learning model’s findings, as the script with the strongest overall proximity to Ethiopic characters suggesting a substantial similarity in character structures. Further, the moderate but consistent similarity metrics predicted for the Caucasian Albanian and Georgian scripts also represent another set of key findings. The variability of several of the Georgian characters in CD while still maintaining good information sharing, in particular, suggest its more complex relationship with the Ethiopic script, which could indicate some fundamental shared principles despite some visual differences.
” that were adopted by old Ge’ez after simple rotation. This is also notable given that the Proto-Ge’ez characters are inherently more angular and sharper than their Ethiopic counterparts. With regard to Latin script, the outcomes are as expected for this control script, which showed the lowest average MI with Ethiopic script with several characters falling below the threshold. The smallest CD (average: 0.0774) and consistently highest MI values (average: 0.7428 bits) predicted for the Armenian script represent one of the key findings of this study which is establishing Armenian script, based purely on the quantitative metrics and focusing solely on the machine learning model’s findings, as the script with the strongest overall proximity to Ethiopic characters suggesting a substantial similarity in character structures. Further, the moderate but consistent similarity metrics predicted for the Caucasian Albanian and Georgian scripts also represent another set of key findings. The variability of several of the Georgian characters in CD while still maintaining good information sharing, in particular, suggest its more complex relationship with the Ethiopic script, which could indicate some fundamental shared principles despite some visual differences.
 (86.3 per cent probability of match) and ቢ (4.75 per cent)), (Ծ—ዐ (91.1 per cent) and ዑ ዕ (8.88 per cent)), (Ը—ሪ (89.2 per cent) and ረ (8.42 per cent)), and (Ա—ባ ቦ (75 per cent and ቢ (19 per cent)). With regard to Caucasian Albanian, the DL model FeedelLigence predicts unexpected characters such as “”, “
(86.3 per cent probability of match) and ቢ (4.75 per cent)), (Ծ—ዐ (91.1 per cent) and ዑ ዕ (8.88 per cent)), (Ը—ሪ (89.2 per cent) and ረ (8.42 per cent)), and (Ա—ባ ቦ (75 per cent and ቢ (19 per cent)). With regard to Caucasian Albanian, the DL model FeedelLigence predicts unexpected characters such as “”, “ ”, and “
”, and “ ” to be similar to the Ethiopic characters “ኔ”, “ኃ”, and “ጥ”, respectively. The case of the “” character is peculiar as it involves a geometric transformation through inversion. Another area of significant interest is the presence of diacritic marks among characters in the three test scripts that exhibit notable similarities and possible dependencies with their Ethiopic counterparts. The structural use of diacritics has historically been a distinguishing feature of the Ethiopic script, its predecessor classical Geʽez, and Indic scripts. Their occurrence in the test scripts, and the ability of FeedelLigence to accurately predict these features, demonstrates the effectiveness of the underlying representation model.
” to be similar to the Ethiopic characters “ኔ”, “ኃ”, and “ጥ”, respectively. The case of the “” character is peculiar as it involves a geometric transformation through inversion. Another area of significant interest is the presence of diacritic marks among characters in the three test scripts that exhibit notable similarities and possible dependencies with their Ethiopic counterparts. The structural use of diacritics has historically been a distinguishing feature of the Ethiopic script, its predecessor classical Geʽez, and Indic scripts. Their occurrence in the test scripts, and the ability of FeedelLigence to accurately predict these features, demonstrates the effectiveness of the underlying representation model.| Discovery through FeedelLigence | Ayele Bekerie’s | ||||||
|---|---|---|---|---|---|---|---|
| ሀ | ሁ | ሂ | ሃ | ሄ |  |
||
| በ | ቡ | ቢ | ባ | ቤ | ብ | ቦ | |
| ገ | ጉ | ጊ | ጋ | ጌ | |||
| ቴ | ቶ | ||||||
| ጣ | ጥ | ጦ | |||||
| ደ | |||||||
| ቀ | ቂ | ቃ | ቅ | ||||
| New characters predicted by FeedelLigence | |
||||||
| ለ | ላ | ል | |||||
| ሰ | ሳ | ስ | ሶ | ||||
| ረ | ሩ | ሪ | ራ | ር | |||
| ዩ | ዪ | ያ | ዬ | ይ | ዬ | ||
| ፒ | ፓ | ፖ | |||||
| ዐ | ዑ | ዕ | |||||
| ወ | ፀ | ጸ | አ | ከ | ዔ | ||
4.2 Geometric transformation of test characters
As described earlier (Section 2.2.1 and Fig. 6), FeedelLigence

Basic geometric transformations like mirror imaging and rotations were used to identify similarities in morphology of characters between Ethiopic and the test character sets. (a) for “Ռ’ (ሁቡብ) (b) Ժ (ዩዪዬ) (c) Ջ (ልይ) (d) Ի (ላሳሶ) (e) Փ (ቀ), and (f) Պ (ጣጦ).
4.3 Limitations of the deep learning model
While the DL model developed in this study serves as a powerful tool for evaluating computational similarities between the Ethiopic script and the three test scripts, as well as two control scripts, it is important to point out that there are certain limitations that could compromise the effectiveness of this DL model. These are discussed below.
- Data quality has a significant influence on the embeddings and representations. One such significant limitation lies in the representation of the Proto-Ge’ez writing system, which is no longer in use and is available only through a single font type—Google’s Noto Sans Old South Arabian font. This results in limited dataset variety and reduced fidelity in terms of both quality and resolution. Notably, Proto-Ge’ez
characters are generally significantly smaller than those of the other scripts examined. Consequently, resizing these character images to 28 × 28 pixels, with the associated loss of input resolution, may not produce a representation equivalent to that of the other scripts, potentially compromising the uniformity of comparative analysis. Related to this, in addition to Proto-Ge’ez characters, the other test-script character images also exhibit some nonuniformity in terms of variation in scale, orientation, stroke width and contrast, background, and capture conditions. Evaluating similarity based on such heterogeneous images could potentially bias the similarity estimates and compromise the generalization across scripts. - Another critical factor is the data imbalance caused by substantial variation in the number of characters across scripts—ranging from twenty-six in Proto-Ge’ez to fifty-two in Caucasian Albanian. This disparity can skew the results of comparative evaluations, particularly when assessing shared information metrics.
- In addition, because the embeddings are aggregated at the group level (i.e., G1—G143), the current formulation lacks character-level granularity. Consequently, the model may not attribute similarity to individual graphemes and also isolate their contributions within each group. In other words, while FeedelLigence
effectively captures script-level affinity or divergence, it may not, however, reveal the specific influence or proximity of individual characters. - Further, it also has to be pointed out that the outcome of the DL model developed here, in general, could be affected by factors such as the image preprocessing algorithms, choice of loss functions (triplet loss), and hyperparameters that all have a significant bearing on the embeddings. Further, the CNN approach used here may overlook positional, combinatorial, and contextual features (e.g., diacritics, ligatures, word boundaries) that could also have an impact on the accuracy of the comparisons.
- Finally, it is important to acknowledge that the quantitative evaluations of shared information, measured through MI and CD, are influenced by the training model’s predefined parameters and computational environment. These values, while accurate, are not absolute but are instead proportionally relative to the specific settings used in this study.
4.4 Historical basis for comparison
Given the striking entropy similarities between the Ethiopic and Armenian scripts predicted by the DL model presented here, and in light of the arguments advanced by several scholars such as the Armenian linguist Sevak, who, based on visual analysis, proposed that the stylistic features of Mashtots’ script are “markedly distinct” and represent “a clear departure” from its natural and geographic neighbors (namely the Persian, Syriac, and Greek scripts previously in use), it becomes both important and necessary to examine the historical evidence. Such an investigation may help determine whether a potential connection between these scripts exists, despite their geographical separation (Sevak 1962).
In particular, questions concerning when and how physical or cultural interactions may have taken place between the civilizations associated with these writing systems, in spite of the considerable distance between them, warrant further investigation. Central to these inquiries is the figure of Mesrop Mashtots—the creator of the Armenian and Caucasian Albanian scripts, and a possible influence on the Georgian script—whose role is pivotal in assessing the plausibility of either direct or indirect contact between these traditions. While Ayele Bekerie has already examined these possibilities to a considerable extent, our discussion extends this inquiry by incorporating a timeline-based approach and exploring additional dimensions of potential cross-cultural interaction, with particular attention to Mashtots’ involvement in script development.
As a starting point, the relevant historical timeline that aligns the emergence of the Armenian, Georgian, and Caucasian Albanian scripts with that of the Ethiopic script, or its predecessor, classical Ge’ez, coincides with the lifetime of Mashtots, spanning approximately from his birth in 362 CE to his death in 440 CE (Fig. 16). This timeline can be further narrowed down to Mashtots’ adulthood years, between 389 CE (when he joined the royal garrison) and 440 CE (Koryun 1962). During this period, the Axumite kingdom of Ethiopia was at its zenith, under the reign of King Ezana (circa 320 CE—360 CE). Ezana is particularly notable for his conversion to Christianity earlier in his reign and the enduring impact of this shift on the cultural and political affairs of the Aksumite state including use of old Ge’ez characters in his coins (Williams 1997). Furthermore, historical evidence points that Byzantine emperors had some contact with the Axumite Negus (emperor) in this period. For instance, in 356 CE, Emperor Constantius II unsuccessfully attempted to enlist King Ezana’s support in an ecclesiastical dispute involving St. Frumentius and Bishop Athanasius of Alexandria. Incidentally, St. Frumentius, the first bishop of Axum, was appointed by Bishop Athanasius in 330 CE (Munro-Hay 1991). Known in Ethiopia as Aba Salama, St. Frumentius, who lived until 383 CE, played a crucial role in the transformation of the “old” Ge’ez with its “abjad” system into the “abugida” system (alphasyllabary) of classical Ge’ez, characterized by consonant-vowel syllabic patterns. This transformation helped the first translation of the New Testament into the Ge’ez language, marking a major milestone in the development of classical Ge’ez. It was also during this period that classical Ge’ez script began to be written from LTR, and that twenty numerals added to the core 182 characters (Kobishchanov 1966; Bender et al. 1976; Dagne 1976). In the context of this study, this milestone that occurred in ∼350 CE is particularly relevant, as it marks the period when these 182 characters of classical Ge’ez first came into use. These characters, therefore, represent the historically accurate and contextually appropriate character set available for any potential interactions during that time. Accordingly, the version of Ethiopic script that was used for training the DL model in this study reflects this historical reality by focusing on the core 182 characters inherited from classical Ge’ez.

Relevant historical timeline to illustrate probable intersection points for sharing of script traditions. The timeline highlights the state of Ethiopic script and its predecessor, “Classical Ge’ez” that corresponds with the time of origin of Armenian, Georgian, and Caucasian Albanian scripts.
Meanwhile, historical evidence suggests that during this same period, Armenia had begun its quest for a distinct script to unite its people under a single political, cultural, and spiritual identity. Some sources indicate that Mashtots initiated efforts to develop a new Armenian script, one that would accurately serve the linguistic needs of the Armenian people, during the fifth year of King Vramshapuh’s reign (ca. 389–414 CE), placing the beginning of this endeavor around 394 CE (Koryun 1962). Most scholarly literature agrees that the new Armenian script was subsequently introduced by Mashtots in 405–06 CE. Despite minor inconsistencies in dates, it is clear that this timeline aligns closely with the period of growth and expansion of classical Geʽez in Aksumite Ethiopia.
Within this historical context, increasing evidence is emerging about the earlier historical interaction between Ethiopian and Armenia, particularly in two key regions: Greater Jerusalem and its surrounding areas (the Levant), and the Sinai Peninsula in Egypt. The first significant location is Jerusalem and its environs, where Ethiopian pilgrims and monks had travelled as early as the fourth century CE, and where Ethiopian monastic activity became well established (Pisani 2025). This is further supported by the discovery of Axumite coins in Jerusalem, indicating that these interactions were active during the period under consideration (Cerulli 1943). Furthermore, as noted by Negussay Ayele, by the time of the Muslim conquest of Jerusalem and the surrounding regions, Caliph Omar (r. 634–644 CE) is said to have acknowledged the physical presence of Ethiopians in Christian holy sites in Jerusalem, including the Church of St. Helena (Ayele 2002). Additionally, the Armenian scholar Anania Shirakatsi recorded instances in the seventh century in which Ethiopian monks assisted with calendar preparation and transcription Geʽez names into Armenian (Pogossian 2021).
Egypt—specifically the St. Catherine monastery in Mount Sinai—emerges as the other likely early contact point. The discovery of palimpsests at Mt. Sinai in 2003 has begun to offer intriguing clues about the writing systems used within the region’s monastic communities. Notably, texts in Ethiopic, Armenian, Georgian, and Caucasian Albanian were found within the same location, raising important, yet still unresolved, questions about the nature and extent of interactions among these communities. Graffiti in some of these scripts have also been identified in the vicinity of the monastery in the Sinai Peninsula, although their utility in determining the depth of scriptural or cultural exchange remains unclear (Pogossian 2021).
These events then raise a relevant and important question: could Mashtots have had the opportunity to interact, directly or indirectly, with Ethiopian pilgrims and monks, whether in Jerusalem, the Levant, or at the Monastery of St. Catherine in Mt. Sinai, between 389 CE (the year he joined the royal garrison) and 405–06 CE (the year he invented the Armenian and Caucasian Albanian scripts)? Historical records indicate that Mashtots began his active missionary activities in 394 CE, traveling through Armenian Mesopotamia and Syria, including the cities of Urha (Edessa) and Amid. He returned to the Armenian capital of Vagharshapat (St. Echmiatsin) in 405 CE, where he was warmly welcomed by King Vramshapuh Arshakouni (Koryun 1962). This effectively narrows the timeline of interest to an 11-year window between 394 CE and 405 CE—critical years in the context of this study. If Mashtots encountered the Ethiopic script, such contact would most likely have occurred during this time frame, particularly during his travels in Syria, where he reportedly met a Syrian bishop named Daniel (also referred to as Oghyump or Olympus) who reportedly introduced him to a writing system that resembled the Ethiopic characters (Koryun 1962; Dagne 1976). This interaction raises the possibility of an Ethiopian presence in Syria during this specific period, perhaps facilitated through interactions between Ethio-Syrian Christian relations. For one, Ethiopian monks are known to have lived in several monastic communities in Egypt alongside Syriac monks. Additionally, contacts between Syriac and Ethiopic monks took place in Jerusalem, where the various Christian communities were represented (Yerevanian 1996; Rapp 2020). Although, more prominently documented from the fifth century onward, there is evidence that Ethiopian monks were present in Lebanon and Syria where some may have inspired the naming of Dayr Mār Mūsā al-Ḥabashī (“Monastery of St. Moses the Ethiopian”), suggesting an established Ethiopian presence in the region (Cerulli 1943; Mason 2011). While concrete evidence remains scarce, it is plausible that this may not have been the first instance that Ethiopian monks would have ventured to the Levant, reaching as far as Syria and Lebanon. As Bekerie argues, it is also conceivable that any connection to the Ethiopic writing system could have passed through Edessa, located on the edge of the Syrian desert, with Bishop Daniel representing an indirect link. This hypothesis, however, remains speculative and underscores the need for further research before any direct historical link can be definitively established. Nevertheless, the growing body of evidence suggests both direct and indirect contact may have played a role.
Taken together, therefore, these historical accounts provide mounting evidence of sustained intercultural contact and underscore the plausibility of script-sharing and mutual influence among Ethiopian and Armenian communities, and by extension, Georgian and Caucasian Albanian communities, as reflected in their respective writing traditions.
5. Conclusions and future direction
This study set out to develop foundational insights towards the potential relationships and shared history between the Armenian, Georgian, Caucasian Albanian, and Ethiopic scripts using techniques of information theory, data sciences, and machine learning. After training a DL model with 28,092 Ethiopic character sets (corresponding to the 182 classical Ge’ez characters), the model was employed to perform similarity and dependence analysis through entropy, CD, and MI metrics based on the style, design, and form of the individual characters. A review of the historical evidence and timeline was also explored to examine the presence of supporting evidence for the potential for interactions that may have facilitated the exchange or influence of writing system traditions. Based on the outcomes of this work, the following conclusions can be drawn:
- Alignment between visual and computational analysis: The FeedelLigence
model and visual inspections approach seem to give a very close agreement in terms of identifying geometrical similarities between these scripts. Overall, this is not entirely unexpected, given that the evidence presented in previous studies, employing morphological, topological, and historical analyses, were grounded in a rational framework. However, it is also useful to note that the DL model was able to identify even more similarities that were not apparent to these frameworks. - Computational proximity among test and control scripts: The FeedelLigence
model revealed significant computational similarities between Ethiopic script and Proto-Ge’ez, followed by Armenian, Caucasian Albanian, and Georgian scripts. These findings suggest potential historical relationships or parallel development patterns among at least some of these writing systems. The prominence of Proto-Ge’ez is not a surprise, as it is the predecessor of Ethiopic writing system. Future research should incorporate historical linguistic analysis to contextualize these computational findings. - Degree of script alignment and dependence: Overall, among the three test scripts, the Armenian script demonstrated the strongest alignment with the reference Ethiopic script, both in terms of embedding similarity and informational content. This suggests the model effectively captures the features of the Armenian script. Caucasian Albanian characters occupied an intermediate position, reflecting a moderate degree of representational alignment. The Georgian script, however, exhibited a modestly lesser similarity and information retention, potentially highlighting unique structural features or areas for improved representation learning in future modeling efforts.
- Armenian–Ethiopic similarity vis-à-vis Proto-Ge’ez: The entropic similarities of the Armenian script with that of the Ethiopic script are almost at the same level as that between Ethiopic and its earlier predecessor Proto-Ge’ez. In other words, the Armenian script exhibits a level of similarity to the Ethiopic script that rivals the natural and expected resemblance between Ethiopic script and its predecessor Proto-Ge’ez, highlighting the comparative closeness of Armenian and Ethiopic scripts.
- Diacritic structures and model representation: A notable finding across the test scripts was the presence of diacritic marks, particularly among characters that share visual or structural affinities with their Ethiopic counterparts. The use of diacritics has long been a distinguishing feature of the Ethiopic script, its predecessor classical Geʽez, and the Brahmic scripts. Notably, none of the influences commonly cited in the formation of the Armenian script such as Greek, Persian, and Syria writing systems include the use of diacritics. Their recurrence in the test scripts and the ability of FeedelLigence to accurately predict them demonstrates the robustness of the underlying representation model and its capacity to capture both subtle orthographic nuances and fine-grained structural features.
- Implications of correlation: This correlation could reflect cultural exchange or influence between the regions where these scripts developed. The machine learning model appears to have identified intrinsic structural and conceptual similarities that transcend surface-level appearance.
- Historical precedent of cultural exchange: Human civilization has long been marked by the sharing, adaptation, and adoption of knowledge across cultures. The Greek, Roman, Persian, and Arabic civilizations offer numerous examples of the free exchange of advances in literature, scripts, mathematics, astronomy, philosophy, and medicine. In this context, it is not surprising that the Armenian, Georgian, Caucasian Albanian, and possibly Edessan scripts may have drawn inspiration from the Ethiopic writing system.
- Validation of machine learning in cultural studies: The work reported here demonstrates that DL models can rediscover cultural, symbolic, and structural links between scripts. The strong alignment of the three scripts with Ethiopic characters, despite the model lacking historical input, suggests genuine architectural similarities worthy of deeper interdisciplinary investigation. Future work can build on this framework to explore script genealogy, cultural transmission, and even possible acts of symbolic adaptation across civilizations.
- Support from historical evidence: The historical discussions and timelines provide growing evidence of intercultural contact and underscore the plausibility of script-sharing and mutual influence among Ethiopian, Armenian, Georgian, and Caucasian Albanian communities and writing traditions.
- Recognition of the contributions of the Ethiopic script: The potential shared heritage and cultural exchange between the Ethiopic writing system and the other scripts examined here underscores the significant role Ethiopia’s writing culture may have played in the broader advancement of human knowledge and cultural expression. This influence should not come as a surprise, given the rich and well-documented historical record of this script.
For future research, given Ge’ez script’s extensive literary heritage, with some scholars estimating the number of Ge’ez manuscripts at around 200,000 (Hable Selassie and Tamerat 1970), the DL model developed here can be extended to trace the evolution of writing styles and variations across different schools of classical Ge’ez studies (Hable Selassie and Tamerat 1970; Nosnitsin 2012). For example, comparing manuscripts from the Hayk Monastery (North Central Ethiopia) with those from other centers of Ge’ez scholarship, such as Debre Bizen (Eritrea) and Debre Libanos (the Shoan Highlands of Central Ethiopia), could yield new insights into the evolution of different strands of Ge’ez sacred literature. Furthermore, the same DL model could be applied to explore the potential origins of the Ethiopic numerals, the theory of whose origins and influence has long been a subject of debate. While some scholars had argued for an indigenous Ethiopian origin, others have proposed external influence from the Coptic and Greek writing traditions (Chrisomalis 2010; Tesfay 2023).
In addition, the same model can be applied to explore similarities and potential relationships and shared history between Ethiopic and the Indic scripts, particularly Devanagari which shares diacritic features with classical Ge’ez and, by extension, the Ethiopic script. Furthermore, as discussed earlier, the implementation presented here is capable of scalable analysis of large corpora with cross-linguistic comparisons. Consequently, FeedelLigence
In summary, this study brings into focus historical cultural interactions that occurred in places perhaps unexpected, yet not entirely surprising interactions that have left a lasting mark on civilizations and literary traditions across communities spanning from Ethiopia to the Caucasus Mountains. By examining relationships among writing systems through techniques of information theory, data sciences, and DL, this work contributes to the growing body of literature on historical intercultural exchanges, with implications for understanding potential future cultural interactions among diverse populations.
At the same time, it is important to underscore that each script examined in this study, regardless of the diverse circumstances surrounding its origin, has played a vital role in the secular and liturgical literature of its respective community. For instance, the Armenian script, which embodies a rich literary and cultural legacy, is a highly refined writing system, widely recognized for its precise phonetic representation of the Armenian language (Olderogge 2022). Notably, the Armenian script and the letter art derived from it have been inscribed by UNESCO as part of the Intangible Cultural Heritage of Humanity. The Georgian script also enjoys a status of “intangible cultural heritage” in its home country and has similarly been inscribed by UNESCO as part of the Intangible Cultural Heritage of Humanity (Shosted and Chikovani 2006), highlighting its importance to the Georgian cultural heritage. Similarly, the discovery of the Caucasian Albanian script marks a significant milestone in the historical and archaeological study of early civilizations in the Caucasus region. The similarities identified among these scripts, therefore, do not diminish their individual historical importance; rather, they underscore the enduring impact of cultural exchange in shaping the trajectory of human civilization and literary heritage.
Furthermore, this work contributes to a broader interdisciplinary discourse, including emerging insights from genetics, that is challenging long-standing historical assumptions. For example, the traditionally accepted theory of the Sabaean origin of Ge’ez, and by extension the Ethiopic script, is now being reexamined in light of recent genetic evidence. These findings indicate a dominant gene flow out of Ethiopia into southern Arabia approximately 2,500 to 3,300 years ago, within the chronological scope of this study focused on the origins of the Ethiopic script, thus opening a potentially rich and under-explored avenue of research.
Acknowledgement
We want to thank Luca Pagani of Università di Padova in Italy for inspiring our considerations of genomics within the broader discussions of culture and writing systems during discussions with SK at his sabbatical.
Author contributions
Daniel Zemene (Conceptualization, Formal analysis, Investigation, Methodology, Software, Visualization, Writing—original draft, Writing—review & editing), Esatu Zemene (Conceptualization, Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing—review & editing), Atharv Sankpal (Methodology, Software, Validation, Visualization), Eskinder Sahle (Formal analysis, Methodology, Writing—review & editing), Vyshak Athreya (Formal analysis, Investigation, Methodology, Software, Validation, Visualization, Writing—review & editing), and Sam Kassegne (Conceptualization, Formal analysis, Investigation, Methodology, Project administration, Supervision, Validation, Visualization, Writing—original draft, Writing—review & editing)
References
et al. (
) ‘Ethiopic Keyboard Mapping and Predictive Text Inputting Algorithm in a Wireless Environment’, ITEs-2004 Proceedings. Addis Ababa: Institute of Ethiopian Studies.
(
) ‘
’,
,
:
–
.
,
(
) ‘
’,
,
:
–
.
(
) ‘Deir Sultan, Ethiopia and the Black World’, MediaETHIOPIA, https://
(
)
.
:
.
(
) ‘
’,
,
:
–
.
et al. (
) ‘The Ethiopian Writing System’, in L. M. Bender, D. J. Bowen, L. R. Cooper, and A. C. Ferguson (eds)
, pp.
–
.
:
.
,
(
) ‘
’,
,
:
–
.
et al. (
) ‘
’,
,
:
–
.
(
)
(
vols).
:
.
(
)
.
:
.
,
. (
) ‘Non-Government Schools in Ethiopia’, in M. L. Bender, J. D. Bowen, R. L. Cooper, and C. A. Ferguson (eds)
, pp.
–
.
:
.
(
)
.
:
.
,
(
) ‘
’,
,
:
.
(
)
.
:
.
(
)
.
:
.
,
(
) ‘N4131R: Proposal for Encoding the Caucasian Albanian Script in the SMP of the UCS’, ISO/IEC JTC1/SC2/WG2 Working Document. Geneva: ISO.
(
) ‘The Ethiopian Language Area’, in M. L. Bender, J. D. Bowen, R. L. Cooper, and C. A. Ferguson (eds)
, pp.
–
.
:
.
(
) ‘Ewosṭatewos’, in
(ed.)
, p.
.
:
.
,
(
) ‘
’,
,
:
–
.
et al. (
) ‘Automated Transcription of Gəʽəz Manuscripts Using Deep Learning’, DHQ: Digital Humanities Quarterly Preview, 17. https://dhq-static.
(
) ‘
’,
,
:
–
.
,
(
)
.
:
.
(
)
.
:
.
(
) ‘HHD-Ethiopic Dataset Repository’, <https://github.com/bdu-
(
)
.
:
.
(
) ‘The Origin of Kartuli (Georgian) Writing (Alphabet)’, in
,
,
(eds),
, pp. 227–34.
:
.
et al. (
) ‘
’,
,
:
–
.
et al. (
) ‘Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices’, in
, pp.
–
.
:
.
(
)
, Trans.
:
.
(
)
, Trans.
,
:
.
,
,
(
)
( (5th ed.) ).
:
.
,
,
(
) ‘Deep Learning for Period Classification of Historical Hebrew Texts’, Journal on Computing and Cultural Heritage. https://jdmdh.
(
) ‘
’,
, No.I. Moscow, the Institute of Oriental Studies of the Russian Academy of Sciences, 2015.
(
) ‘
’,
,
:
–
.
(
) ‘
’,
,
:
–
.
(
) ‘The Breath of God: A Short History of the Armenian Alphabet’, Providence Magazine, https://
(
)
.
:
.
(
)
.
:
.
,
(
)
.
:
.
,
,
(
) ‘
’,
.
(
) ‘
’,
,
:
–
.
(
) ‘L’Arménie et l’Ethiopie au IVe siècle: À propos des sources de l’alphabet arménien’, in IVe Congresso internazionale di studi etiopici, I. Rome: Accademia nazionale dei Lincei.
(
) The History of Armenian–Ethiopian Relations, Trans. O. Alizade, in Proceedings of the 1st International Congress of Ege Social Sciences Graduate Studies, pp.
–
.
et al. (
) ‘
’,
,
:
–
.
(
) ‘The history of Ethiopian–Armenian Relations I–III’, Revue des études arméniennes,
:
–
.
(
)
.
:
.
(
) ‘The Ethiopian and Eritrean Orthodox Church in Jerusalem during the Early Solomonic Period: Evidence from Ethiopic Manuscripts’, in
,
,
,
(eds)
, pp.
–
.
:
.
(
) ‘
’,
,
:
–
.
(
) ‘From the Holy City to the Holy Mountain: The Movement of Monks and Manuscripts to the Sinai’, in
,
,
,
,
(eds)
, pp.
–
.
:
.
(
)
.
:
.
(
) ‘
’,
,
:
–
.
(
). ‘The Armenian Alphabet’, in
(eds)
, pp.
–
.
:
.
,
(eds) (
)
.
: Österreichisch-armenische Studiengesellschaft.
(
)
.
:
.
,
(
) ‘
’,
,
:
–
.
(
)
,
–
.
:
.
(
) ‘Armenian, Georgian and Albanian Communities between the Fourth and Eleventh Centuries’, Handbook of Oriental Studies: Section 1: The Near and Middle East. Leiden: Koninklijke Brill NV.
(
) ‘
’,
,
:
–
.
(
) ‘
’,
,
:
–
.
(
) ‘
’,
,
:
–
.
(
) Armenian (U+0530–U+058F), The Unicode Standard, Version 17.0, https://www.unicode.org/
(
) ‘Caucasian Albanian (U+10530–U+1056F), The Unicode Standard, Version 17.0’, https://www.unicode.
(
) ‘Ethiopic (U+1200–U+137F), The Unicode Standard, Version 17.0’, <https://www.unicode.org/
(
) ‘Georgian (U+10A0–U+10FF), The Unicode Standard, Version 17.0’, https://www.unicode.
(
) ‘Ethiopic Extended-A (U+AB00–AB2F)’, https://
,
(
) ‘The Poet Identification Using Convolutional Neural Networks’, in Proceedings of the International Conference on Computing and Information Technology, pp. 179–87. Berlin: Springer Nature.
,
,
(
) ‘Deep Learning for Ethiopian Geʽez Script Optical Character Recognition’, in Proceedings of the Tenth International Conference on Advanced Computational Intelligence (ICACI), pp. 540–5. New York: IEEE.
(
) ‘Ethio-Semitic in General’, in
(ed.)
, pp.
–
.
:
.
(ed.) (
)
.
:
.
(
)
.
:
.




